Training
Consumer Hardware, Big Results
Day 2: Training and Deploying SOTA Document AI Models on a Budget
Day 2: Training and Deploying SOTA Document AI Models on a Budget
How we built production-grade OCR and reasoning models using consumer hardware, efficient fine-tuning, and reinforcement learning
This is Day 2 of a 7-part series on building Cernis Intelligence - Document Intelligence for the AI era.
The Document AI Challenge
Traditional OCR engines like Tesseract excel at printed text, but catastrophically fail on real-world document complexity:
Handwriting obstacles:
- Character ambiguity: handwritten 'a' vs 'o', '1' vs 'l', '0' vs 'O'
- Style variation: cursive vs print, individual writing patterns
- Contextual inference: humans disambiguate through context; traditional OCR cannot
Mathematical notation barriers:
- Spatial relationships: superscripts/subscripts (x² vs x₂), fractions (a/b), matrices
- Symbol confusion: Greek letters (α, β, γ) vs Latin (a, b, g), operators (× vs x)
- 2D structure: OCR treats formulas as linear text, destroying spatial relationships
Commercial model APIs like GPT-4o and Gemini excel at complex document understanding, but at $0.01–$0.05 per page, processing millions of documents costs $10,000–$50,000 per month.
This is the story of how we built two production-grade models, CernisOCR and Cernis-Thinking, that match frontier model performance on document tasks, trained on a single RTX 4090 for under $50 in GPU time.
Part 1: CernisOCR - Unified Multi-Domain OCR with Supervised Fine-Tuning
The Vision Language Model Advantage
Modern VLMs (GPT-4o, Gemini, Qwen2.5-VL) outperform traditional OCR because they:
- Learn contextual relationships: "The cat sat on the ___" → "mat" (not "mot")
- Handle style variation: Trained on diverse handwriting datasets
- Multi-modal understanding: Combine visual features with language priors
- Spatial reasoning: Understand 2D layout of mathematical formulas
We chose Qwen2.5-VL-7B, an open-source 7B parameters model with strong vision-language capabilities that beat GPT4 vision and a host of other vLM in multiple rankings as our base model.
Training Strategy: Parameter-Efficient Fine-Tuning
Rather than full model fine-tuning (expensive, slow, requires massive GPUs), we used LoRA (Low-Rank Adaptation):
Efficiency gains:
- Trains on single RTX 4090 (consumer GPU)
- Requires only 16GB VRAM (4-bit quantization)
- Training time: 4 hours (vs days for full fine-tuning)
- Cost: <$50 in GPU time
Dataset Composition: 10,000 Balanced Samples
We curated a diverse dataset spanning three key OCR domains:
1. LaTeX OCR (3,978 samples)
- Mathematical formulas (printed and handwritten)
- Image-LaTeX pairs: arithmetic, algebra, calculus, linear algebra, probability
- Output format: LaTeX for unambiguous representation
2. Invoice & Receipt Extraction (2,043 samples)
- Structured documents requiring JSON output
- Fields: vendor names, amounts, dates, line items
- Teaches model structured extraction patterns
3. Handwritten Text (3,978 samples)
- Cursive and print writing styles
- Diverse handwriting patterns and document types
- Plain text output
Training Results: 97.6% Loss Reduction
The model achieved 97.6% loss reduction, demonstrating efficient learning across all three document types within a single unified architecture. This metric indicates rapid convergence despite the diversity of tasks.
Multi-domain capability eliminates the need for separate models:
- Single model handles printed text, handwriting, and mathematical notation
- Reduces deployment complexity and inference costs
- Maintains strong performance across all domains
Deployment: Open-Source and Production-Ready
CernisOCR is available on HuggingFace.
Part 2: Cernis-Thinking - Adding Reasoning with Reinforcement Learning
Beyond Supervised Learning: The Need for Reasoning
While CernisOCR excels at extraction, many complex document tasks require reasoning.
GRPO: Group Relative Policy Optimization
Instead of traditional SFT on example outputs, we used GRPO to teach the model to maximize rewards for correct, well-structured outputs.
The Multi-Component Reward Function
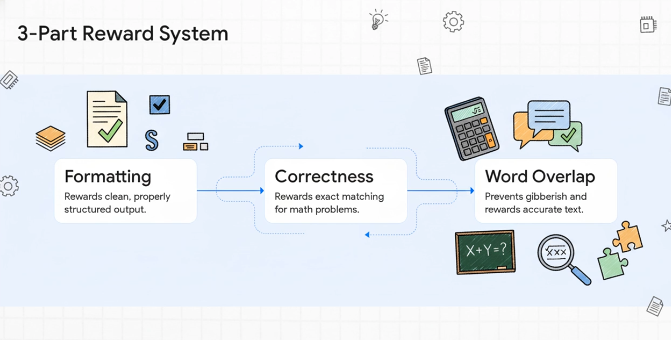
We designed three complementary reward mechanisms:
1. Formatting Rewards
Incentivizes proper structure using <REASONING> and <SOLUTION> tags and penalizes excessive artifacts and malformed output.
2. Task-Specific Correctness Rewards For example, the model is rewarded for exact numeric matching for math problems.
3. ROUGE-Style Word Overlap Applied to OCR tasks to prevent training on gibberish while providing feedback on text-heavy tasks.
What Reasoning Unlocks
Cernis-Thinking demonstrates four primary capabilities:
1. Mathematical Reasoning
<REASONING>
The problem asks for the area of a circle with radius 5cm.
Formula: A = πr²
Substituting r = 5: A = π(5)² = 25π ≈ 78.54 cm²
</REASONING>
<SOLUTION>
78.54 cm²
</SOLUTION>
2. LaTeX Formula Recognition Handles complex notation with structural validation:
- Recognizes nested fractions, integrals, summations
- Validates LaTeX syntax before output
- Checks rendering equivalence
3. Invoice Data Extraction with Verification
<REASONING>
Detected vendor: "Acme Corp"
Line items: $150 + $75 + $200 = $425
Tax (8%): $34
Total should be: $425 + $34 = $459
Document shows: $459 ✓
</REASONING>
<SOLUTION>
{"vendor": "Acme Corp", "subtotal": 425.00, "tax": 34.00, "total": 459.00, "verified": true}
</SOLUTION>
4. Handwritten Text Transcription Uses context to disambiguate ambiguous characters:
- "The year 1999" (not "l999")
- "Total: $100" (not "$l00")
Key Takeaways: SOTA on a Budget
What We Learned
-
Consumer hardware is sufficient for training and deploying SOTA domain-specific models that rival larger general models in performance.
-
Data quality > quantity for RL. We also learned that reward function design matters more than dataset size.
-
Open-source foundations accelerate development. Lastly, we're huge fans of the OSS spirit. Qwen2.5-VL-7B provides a strong vision-language base, while HuggingFace and RL startups like unsloth make training very simple.
What's Next
Tomorrow, we will talk about how we deploy these models in production at scale.
Conclusion
With strategic dataset curation, parameter-efficient fine-tuning, and reinforcement learning, small teams leverage OSS to train state-of-the-art document intelligence models.
The future of document AI is open-source, accessible, and ready to deploy.